robots.txt 是一个位于网站根目录的纯文本文件,用来告诉搜索引擎爬虫哪些页面或资源可以被访问和索引,哪些不可以。它通过定义特定的规则来控制搜索引擎对网站内容的爬取行为,对于网站SEO来说是两个基本的搜索引擎爬取文本贵。
前两天谷歌更新了其robots.txt文件的使用描述,对于不支持的字段将被忽略。
根据最新文档,robots.txt文件中只有四个字段被谷歌官方支持,仅供支持的字段为:
上述之外的指令字段将被忽略。因此,如果你的独立站使用了其他指令字段,将被Google抓取时忽略掉。
如上4类的含义和用法简单例举如下:
User-agent:表示允许所有搜索引擎爬虫对象,默认都为* ,标识规则适用于所有爬虫。
Disallow:表示禁止访问网站的内容,爬虫不能爬取Disallow目录下属的任何页面。
Allow:允许所有爬虫访问特定路径,即可访问某些目录下的文件
Sitemap:告知爬虫网站的 sitemap.xml 文件位置,帮助它们更好地发现和爬取页面。
常见的写法:
User-agent: * (表示允许所有搜索引擎爬虫(如 Googlebot、Bingbot)访问该网站)
Disallow: (后面没有任何路径,表示不禁止任何页面的爬取,也就是说整个网站对所有爬虫都是开放的。)
Sitemap: https://www.example.com/sitemap.xml
robots规则只针对所有爬虫。表示任何爬虫可以爬取任何文件。
User-agent: Googlebot
Disallow: /
robots规则只针对谷歌的爬虫。 表示禁止 Googlebot 访问整个网站,其他爬虫则不受影响。
User-agent: *
Disallow: /private/
robots规则针对所有爬虫。表示禁止爬取网站的 /private/ 文件夹及其所有内容,其他部分的网站是可以访问的。
User-agent: *
Disallow: /usercenter/
Disallow: /admin/
Sitemap: https://www.wmeasy.com/sitemap.xml
robots规则针对所有爬虫,禁止访问管理员和用户中心的页面,并提供网站地图的 URL,帮助搜索引擎更好地索引网站。
那么回头再说说被弃用或者说本来就没支持的常见指令有哪些呢:
Crawl-delay: 3 ,表示爬取间隔的,秒为单位,对于一些大站,频繁爬取可能搞崩溃服务器的,像博客园就有这样的例子。
Noindex: /admin/ ,该字段告诉爬虫不要将某些页面或文件夹的内容编入索引,防止它们出现在搜索结果中。
实际上谷歌从未正式支持 Noindex 指令,但以前某些爬虫可能会遵守这一规则。现在,使用 meta 标签或a标签中的 noindex 指令才是推荐的做法。
Nofollow: /private/ 表示爬虫不要跟随页面中的链接,主要用于外链或广告链接等,防止传递权重或进一步爬取被禁止的页面 。
同样谷歌不支持在 robots.txt 中使用 Nofollow,。而是在页面中通过 HTML 标签属性来实现。
Noarchive: / 表示搜索引擎不要缓存页面的副本,也就是防止页面被存档在搜索引擎的缓存中。
其实对于小站来说,本来也没有多少访问量,即便不写也不会造成太大问题哦。对于内容不少的大站,来看看模范shein的:
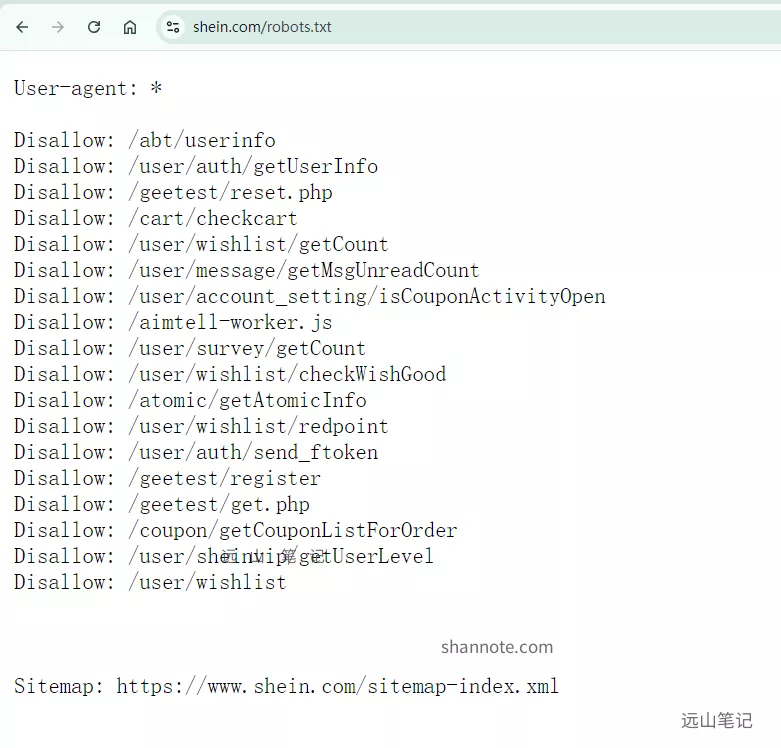
刷新